R을 활용한 히스토그램(histogram) 그리기
R을 활용한 데이터 시각화 초급 세 번째로 배워볼 그림은 히스토그램(histogram)입니다.
우리가 연속형 데이터를 시각화할 때 많이 쓰는 그래프입니다. 한번 배워볼까요?
1. 데이터 준비하기
히스토그램을 그리기 위한 데이터는 지역별 기상데이터입니다.
2018년 7월 9일부터 16일까지 관측된 기온, 습도 등이 포함된 데이터입니다.
2. R 코드
먼저 데이터를 불러와서 weather이라는 object에 저장합니다.
#1. 데이터 불러오기
setwd("C:/data")
weather <- read.csv("지역별 기상 데이터.csv")
그리고 데이터를 분석하고 그림을 그리기 전에 데이터의 생김새를 살펴봅니다. 데이터가 잘 불러와졌는지 확인하기도 하고요.
저는 보통 5개 함수를 써서 살펴봅니다.
#2. 데이터 생김새 파악하기
head(weather) # 데이터 상위 6개 보기
tail(weather) # 데이터 하위 6개 보기
nrow(weather) # 데이터 row수 보기
summary(weather) # 기본통계량 보기
str(weather) # 변수 특성 확인 등 구조 확인
이제 히스토그램을 그려보겠습니다. 해당기간의 지역별 평균기온에 대한 히스토그램을 그려봅니다.
ahot <- weather$평균기온
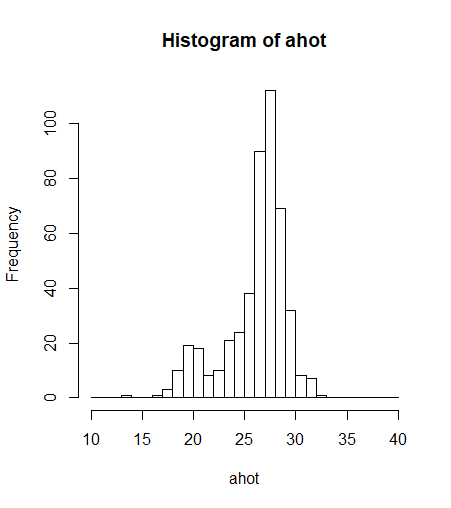
histo <- hist(ahot)기본적으로 구간의 빈도(Frequency)를 보여줍니다. 25도에서 30도 사이의 값이 가장 많은 것을 알 수 있습니다.

breaks 옵션을 사용해서 간격을 조정할 수 있습니다.
# 간격 조정(breaks)
hist(ahot, breaks=24)
hist(ahot, breaks=seq(10,40,by=1))
왼쪽 그래프는 breaks를 24로 설정해서 그린 히스토그램 입니다. 구간을 24개의 구간으로 나눠서 그리자는 옵션입니다.
오른쪽 그래프는 seq함수를 사용해서 구간을 직접 설정했습니다.

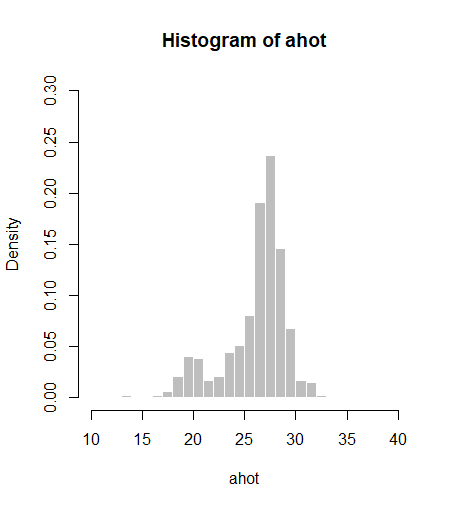
빈도수 기반이 아닌 확률밀도 기반으로 히스토그램을 그릴 수 있습니다. prob옵션을 TRUE로 설정하면 그릴 수 있습니다.
혹은 freq 옵션을 FALSE로 설정하면 됩니다.
# 확률밀도 히스토그램(prob, freq)
hist(ahot, breaks=seq(10,40,by=1), col="grey", border="white",
prob=T, ylim=c(0,0.3))
hist(ahot, breaks=seq(10,40,by=1), col="grey", border="white",
freq=F, ylim=c(0,0.3))
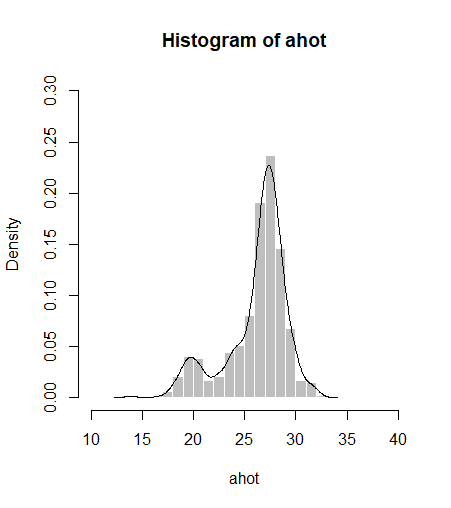
마지막으로 확률밀도(Density) 기반으로 그린 히스토그램에 라인을 추가할 수 있습니다.
# 확률밀도 히스토그램에 라인 그리기(lines)
lines(density(ahot))
히스토그램에서 가장 중요한 옵션은 breaks 입니다.
구간을 어떻게 설정하냐에 따라 히스토그램의 모양이 달라지고 시각적으로 데이터를 쉽게 확인할 수 있기 때문이죠!
R을 활용하여 히스토그램 그리기였습니다. 감사합니다.
'R 시각화' 카테고리의 다른 글
| [R 시각화] ggmap, get_naver 를 활용한 대한민국 지도 그리기 (0) | 2022.03.15 |
|---|---|
| [R 시각화] reorder 함수(function) 활용해서 ggplot2 그래프 정렬하기 (0) | 2022.03.15 |
| [R 시각화] 원그래프(pie chart) 그리기 (0) | 2022.03.15 |
| [R 시각화] 막대그래프(barplot) 그리기 (2) (0) | 2022.03.15 |
| [R 시각화] 막대그래프(barplot) 그리기 (1) (0) | 2022.03.15 |



